Test
Static analysis of C and C++ source code
Static analysis is the process by which different types of facts are extracted from source code. These facts range from basic data such as syntactic and semantic information, dependencies (e.g. call graphs, control flow graphs, type usage graphs, inheritance trees), up to refined data such as software quality metrics, design patterns, and UML diagrams.
Static analysis of C and C++ is probably the most challenging among all mainstream programming languages in existence. Difficulties include a context-dependent grammar, very complicated semantics, numerous dialects, the preprocessing step, and a compilation model relying on explicitly specified header locations.
A new C/C++ analyzer design
Although many C/C++ analyzers exist, very few of them are truly usable in practice for complex tasks and on industry-size code bases. We studied the design of several existing analyzers, and developed our own efficient and effective C/C++ static analyzer, with the following features
- robustly handles possibly incomplete and incorrect code
- supports dialects (Visual C++, gcc, C89/90, C99, ANSI/ISO C++, and Kyle C)
- implements the C/C++ standard semantics almost entirely
- handles almost all template features
- is easy to run on several platforms (Windows, Linux, Solaris, Mac OS X)
- runs efficiently on code bases of millions of lines
- integrates a C/C++ preprocessor
- exports full preprocessor, syntactic, and semantic information
- adds plug-ins for information querying, analysis, and visualization
Architecture
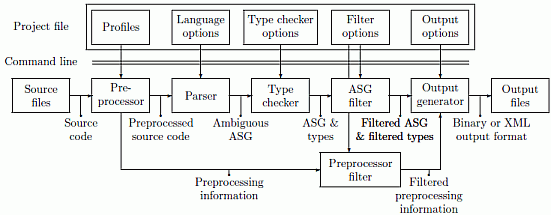
The architecture of our analyzer is shown below. It exhibits several interesting different points in contrast to other existing C/C++ analyzers. The design is a feed-forward pipeline. Note the total absence of feedback loops from semantic analysis to parsing or parsing to preprocessing.
Parser
We use an inherently ambiguous C/C++ grammar and a Generalize Left-Reduce (GLR)parser which creates a forest of parse trees. This massively simplifies the grammar design by moving disambiguation in the semantic analysis pass.
Semantic analyzer
The semantic analyzer creates type information for all syntax constructs produced by the parser. We also use this information to disambiguate, i.e. reduce the parse forest to a single parse tree.
Error recovery
We handle incorrect or incomplete code at several levels:
- in the lexer, incorrect tokens sre transparently skipped
- in the parser, incorrect constructs at block and declaration level are replaced by a special 'garbage' syntax node
- in the semantic analyzer, incorrect constructs at all levels are silently left without type information
All in all, this design delivers the most correct information possible, without blocking further analysis.
Filtering
We allow filtering information before output at several levels
- preprocessor, syntax, or type information can be optionally skipped
- data from system headers can be skipped
- data which is not referenced (used) can be skipped
This allows selectively minimizing the output size.
Output
All information is saved in a run-lengh-encoded format which can be further compressed with the advanced algorithm. Data is also optimized for fast querying using a multilevel hashing method.
Querying
We have developed a pattern-based query system for the output data. Patterns can be declared in a simple, concise, compositional XML-based language. This allows searches as simple as "all variables called abc*" or as complex as "all template methods overriding func and whose third parameter is a subtype of T". Queries over millions of items occur in subsecond time.
Metrics
Code metrics are implemented simply as counts over suitable queries. We have implemented classical metrics such as McCabe's complexity, coupling, cohesion, fan-in, fan-out, and various object-oriented metrics described in the book of Lanza and Marinescu.
Visualization
Several visualizations can be applied to the extracted facts, such as table lenses, UML diagrams and metrics, pixel-based code views, and hierarchically bundled edges. Several such visualizations are grouped in an Integrated Reverse-Engineering Ennvironment described here.
Comparison
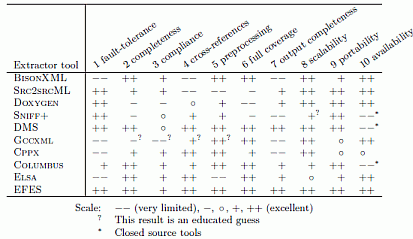
A succinct comparison of our analyzer with other well-known analyzers is presented below. For details, see References below.
Applications
We used our C/C++ analyzer in several software assessment projects involving industrial code bases of millions of lines of code. These projects are described in publications 129, 125, 104, and 100, available here.
Software
An independently maintained, up-to-date, version of this C/C++ analyzer is available here.
References
The original work leading to our C/C++ static analyzer is described in the MSc thesis of F. Boerboom and A. Janssen.
This work is further described in publications 116, 107, 104, and 99 available here.