Test
Fact extraction and visualization from gcc
gcc is one of the most widely used compiler suites for C and C++ code. It supports a wealth of C/C++ dialects, efficient code generation, and cross-compilation for many platforms.
Although widely used, gcc itself does not provide easy-to-use mechanisms for static code analysis techniques such as structure-and-dependency extraction, which are required in reverse engineering activities in software maintenance. Such data typically involves:
- a hierarchy of folders, files, namespaces, classes, and functions
- dependencies e.g. function calls, symbol uses, inheritance, and includes
- attributes e.g. symbol names, type, visibility, linkage, and access rights
The entire data can be modeled as a compound attributed graph.
We have developed several approaches to offer such features to typical users of gcc. The central element has been ease of use: Developers want to extract and examine program structure with minimal effort.
Structure-and-dependency analysis for C/C++ with oink
In the first approach, from the gcc suite, only the cpp preprocessor. The architecture of our solution is shown below.
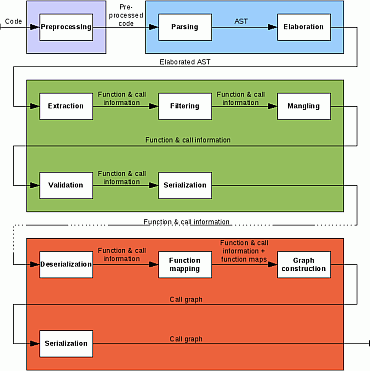
For actual extraction, we extend the open-source oink C/C++ static analyzer to collect raw facts such as syntax and type information. Next, we refine these facts to produce simpler and more useful dependency graphs. That is, we
- perform inter-translation unit linking to relate callers with callees
- resolve as much virtual calls as possible with static analysis
- resolve implicit calls to default constructors, destructors, and intrinsics
- identify program entry and exit points, dead code, and connected components
- simplify usage by automatic compiler, archiver, and linker wrapping
- filter the extracted facts on user-defined criteria
- serialize the extracted facts for further analysis
Structure-and-dependency analysis for C/C++ with gcc
Applications
We have applied our structure-and-dependency extractors and associated visualizations to very large and complex software systems, including Mozilla Firefox (over 1.5 M lines of C/C++) and oink (over 800 K lines of C++). The extraction time is comparable to compilation, and can be automatically run via the systems' makefiles with no changes.
The resulting structure-and-dependency graphs can be exported in various formats, including Tulip and an SQL format used by SolidSX.
Software
Our oink-based structure-and-dependency extractor software is available here for Linux systems. It was tested on an Ubuntu installation, but it should also work on other distributions.
Building the software
Check the README file in the distribution.
Running the software
Check the README file in the distribution. More details are given in the MSc of H. Hoogendorp available here.
Sample datasets
Datasets from several large systems, including Bison, Oink, and Mozilla, will be soon available here. For additional datasets, which are not uploaded due to their sheer size, please contact prof. Alex Telea.
Related projects
Our more complex C/C++ static analyzer provides a superset of the functionality described here, independently of gcc or oink.
Publications
See papers 128, 123 available here.