Project Proposal: Visual Modeling and Design of Large Data-Intensive Applications
Background
The Target holding is a multi-organization venture focused on the processing of very large amounts of data (petabytes) acquired from sensors, such as CCD. Data processing tasks involve several of the following steps:
- modeling the data space by means of multivariate relational databases
- efficiently computing several metrics and extracting relevant features from the data (shapes, signals, outliers, distributions, clusters)
- presenting the analysis results in an easy-to-understand way to non-technical end-users such as scientists and business analysts
Goal
The Target software infrastructure consists of a large set of data processing tools, databases, and platforms, all connected in a distributed architecture. Given the complexity of this architecture, it is currently quite hard for developers to extend or modify the existing processing pipeline.
In this project, we study the feasibility of a visual modeling solution to support the above use-case. Ideally, such a solution should
- allow users to 'compose' existing processing blocks visually to create new computational and data processing pipelines
- monitor and control the execution of existing pipelines graphically
- examine the results of a processing pipeline interactively
- design and implement new computational blocks in an easy manner, so that adding them to the existing infrastructure is simple
Visual programming
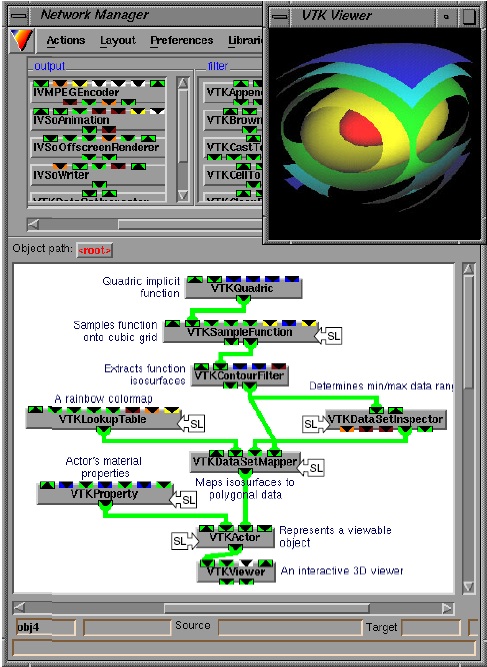
Visual programming is a possible solution to be investigated for this project. Visual programming offers graphical representations of processing units to end-users and allows these to interactively assemble units to construct computational pipelines. The image below shows a snapshot from such a visual programming environment.
Challenges
Although many such visual programming environments exist, several specific challenges exist in the current project
- which visual programming environment fits best the concrete user context
- how to integrate very large, hybrid, data sources that may reside in different types of databases
- how to design the system to work in a distributed environment
- how to easily integrate existing computational code in the new architecture
- how to best visualize dependencies between computational processes
Workplan
The project will cover the following steps:
1. Literature and context study
In this step, the current context of the Target architecture is studied and compared with existing state-of-the-art visual programming solutions. The requirements of the Target context are made explicit. An optimal solution is chosen for the development of the Target-specific visual programming requirements.
2. Architecture
An architecture for the proposed system is designed, and verified against the requirements elicited at step 1. Implementation technologies are also made explicit. Care is taken to define both an architecture for the visual programming environment and specifications for the software components that are to be integrated in this environment.
3. Design and implementation
The various building blocks of the architecture proposed above are identified and implemented. The solution is tested with a simple proof-of-concept application running on the actual Target systems and using the actual Target data sources.
4. Incorporation of existing software (optional)
The existing computational software blocks in the Target environment are incorporated in the current solution. In parallel, existing Target applications are re-built and tested using the new solution. This step may be covered minimally if the project is done by a single student.
Deliverables
- operational software implementing the visual programming architecture described above
- report (20..40 pages) describing the architecture, design, implementation, and a short user/developer manual
- results (description of actual use-cases with snapshots)
Requirements
The candidate(s) for this project should ideally have
- (very) good software development experience (Linux, Python)
- good analytical skills
- object-oriented design skills
- will to work in a R&D facility, close to an industrial IT context
Evaluation
The project will be evaluated as follows
- analysis of problem and solution space (completeness, clarity, justification; 30%)
- quality of delivered solution (match to the identified requirements; 30%)
- quality of final report (completeness, readability, clarity; 20%)
- quality of implementation (ease of use, code documentation; 20%)
Participants
The project can be done by a single student or two students. If done by two students, then
- step 4 becomes mandatory
- requirements in step 1 will become more challenging (e.g. scalability, ease-of-use, ease of integration of existing code blocks)
- work can be divided as follows
- student 1: visual programming interface, usability aspects
- student 2: component model, ease-of-integration of existing code
- both students: applications (step 4)
Contact person
This project is supervised by prof. Alexandru Telea.
From the Target holding, the project is supervised by Rolf Fokkens (Rolf.fokkens@target-holding.nl)
More information (in Dutch) is available here.